SREエンジニアとは?仕事内容・平均年収・市場価値を高める5つの戦略
タジケン
テクラル合同会社

現代のシステム開発において、サービスの安定稼働と新機能の迅速なリリースは、多くの企業が直面する共通の課題です。この課題を解決し、システムの信頼性をソフトウェアエンジニアリングのアプローチで高める専門家がSREエンジニアです。本記事では、SREエンジニアとは何か、その仕事内容、平均年収、そして市場価値を高めるための具体的なロードマップを詳しく解説します。
SREエンジニアとは?役割とDevOpsとの違い
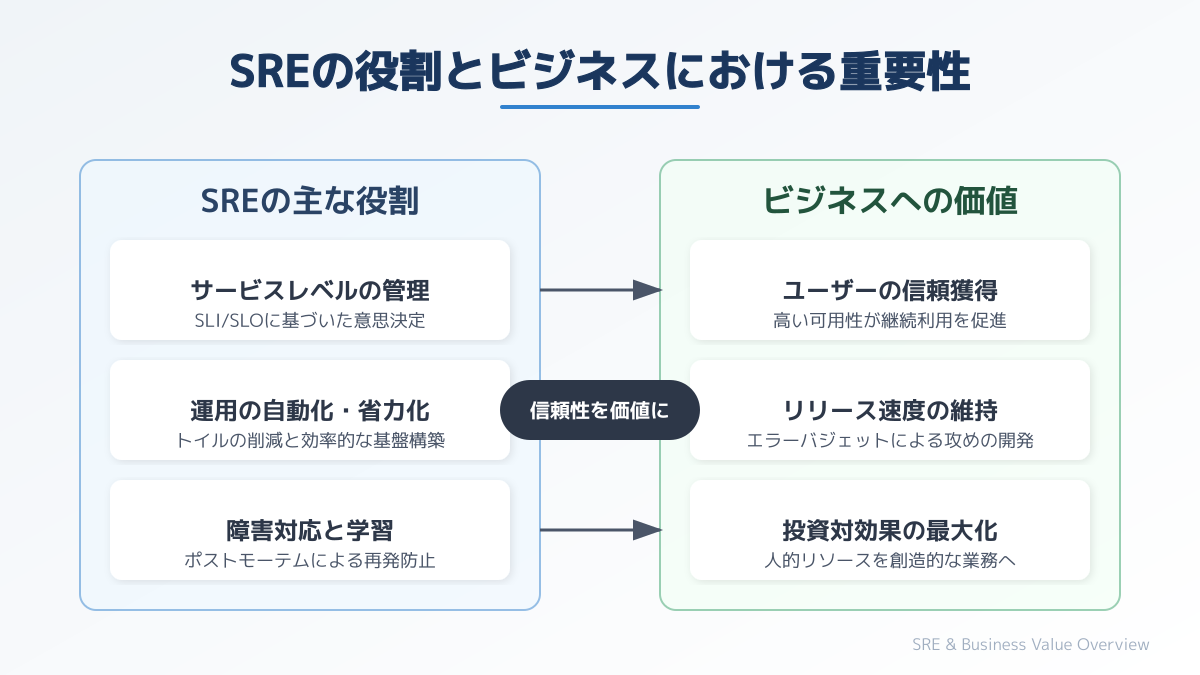
SRE(Site Reliability Engineering)は、Googleが提唱したシステム管理とサービス運用の方法論です。SREエンジニアとは、このアプローチを用いてシステムの信頼性向上と開発スピードの両立を実現する専門職を指します。
SREエンジニアの定義と役割
従来のインフラエンジニアが手作業でのサーバー保守を主としていたのに対し、SREエンジニアはソフトウェアエンジニアリングの手法で運用課題を解決します。システムの障害をゼロにすることを目指すのではなく、ビジネス要件とユーザー体験の観点から「適切な信頼性レベル」を設計することが最大の役割です。
DevOpsの思想を実装するSRE
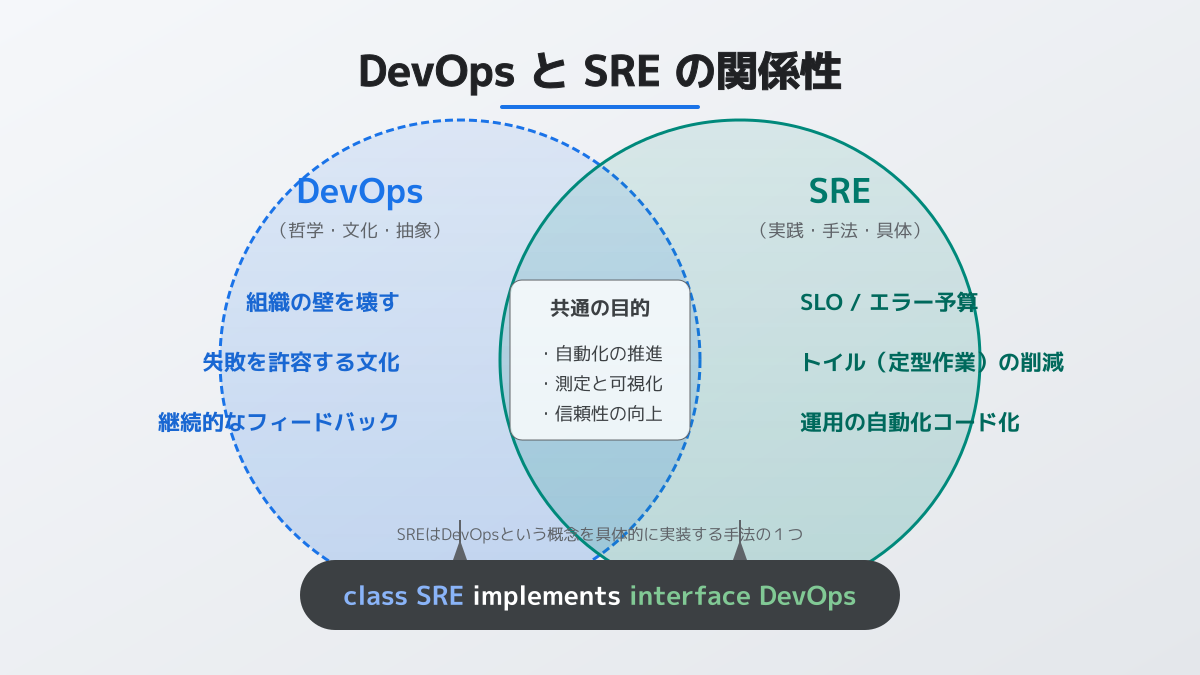
SREを深く理解する上で欠かせないのが、DevOpsという概念との関係性です。DevOpsが「開発と運用の壁をなくし、迅速に価値を届けるための思想や文化」であるのに対し、SREはその思想を具体的に実装・実践する手法を指します。つまり、SREエンジニアはDevOpsの抽象的な文化をシステム上で体現する役割を担っています。
SREを支える3つの重要概念
SREの運用は、以下の3つの主要な概念によって支えられています。
- SLI/SLO:SLI(サービスレベル指標)は可用性やレスポンスタイムといった現在地を示すデータであり、SLO(サービスレベル目標)はその指標に対して達成すべき目標値です。
- エラーバジェット:SLOから導き出される「許容可能な障害の予算」です。この予算を基準に、新機能のリリースを推進するか、システムの安定化に注力するかを判断します。
- トイル削減:手作業で繰り返される運用業務(トイル)を自動化し、本質的なアーキテクチャの改善に時間を割く取り組みです。
SREエンジニアの具体的な仕事内容
SREエンジニアは、前述の概念を基に日々の業務を遂行します。ここでは、具体的な仕事内容と実務のサンプルを解説します。
インフラのコード化(IaC)と自動化
トイルを削減するため、Terraformなどのツールを用いてインフラの構築や設定をコード化(IaC)します。また、GitHub ActionsなどのCI/CDパイプラインを整備し、アプリケーションのデプロイを自動化することで、人的ミスの防止とリリース速度の向上を実現します。例えば、従来は手動で数時間かかっていたサーバーのプロビジョニングや設定変更を、コード実行により数分で完了させるような業務が該当します。
監視設計とキャパシティプランニング
システムがSLOを満たしているかを継続的に確認するため、DatadogやPrometheusなどのツールを用いて監視基盤を構築します。単にサーバーの死活監視を行うだけでなく、ユーザーの決済エラー率や画面表示の遅延など、ビジネス指標に直結するアラートを設計します。また、大規模なキャンペーン等によるトラフィックの増加を予測し、事前にクラウドリソースを拡張するキャパシティプランニングも重要な業務です。
インシデント対応とポストモーテム
障害発生時には迅速に復旧作業を行い、その後「ポストモーテム(事後検証)」を実施します。個人のミスを責めるのではなく、ミスを誘発したシステムの根本原因を特定し、再発防止策を講じる「非難なき文化」を徹底します。インシデント対応の効率化を進める際は、【そのまま使える】生成AIプロンプトのテンプレートと書き方のコツ などを参考に、AIへの指示出しを標準化することも有効な手段です。
【実務サンプル】SREエンジニアのインシデント対応フロー
より具体的にイメージできるよう、実務におけるインシデント対応のサンプルフローを紹介します。
- 検知:Datadogのアラートにより「決済APIのレスポンスタイムが規定のSLOを10%下回った」ことをSlack上で検知。
- 一次対応(トリアージ):ログと分散トレーシングを確認し、特定のデータベースクエリの遅延が原因であると特定。影響範囲を直ちに開発チームに共有。
- 暫定復旧:データベースのリソースを一時的にスケールアップし、正常なレスポンスタイムに復旧させる。
- ポストモーテム作成:インシデント終息後、開発チームと共同で「なぜ遅延したのか」「監視漏れはなかったか」をドキュメント化。
- 恒久対応(改善):次スプリントで該当クエリのチューニングやキャッシュ層の追加を行い、同じ障害が起きない仕組みを実装する。
SLI/SLOとエラーバジェットの実践的な運用方法
SREの概念を実際の現場でどのように運用するのか、具体的な実践方法を解説します。
ビジネス目標から逆算するSLO設計
SLOは運用担当者が単独で決めるものではありません。プロダクトマネージャーや開発チームと協議し、「どこまでシステムが安定していればユーザーの満足度を維持できるのか」というビジネス上の要件から逆算して適切な目標値を設定します。
エラーバジェットを基準としたリリース判定
エラーバジェットが残っている間は、多少のリスクを取ってでも新機能のリリースを積極的に推進します。逆に予算を使い切ってしまった場合は、新規開発を一時停止し、システムの安定化にリソースを集中させます。客観的なデータに基づいて「攻め」と「守り」の判断を下すことが、SREの最大の価値です。
アラート疲れを防ぐ監視のベストプラクティス
重要度の低い通知が頻発する監視設定では、エンジニアの疲弊を招き、本当に致命的な障害を見落とす危険性が高まります。ユーザーの体験に直結するアラートのみを厳選し、それ以外は自動復旧の仕組みを構築することが求められます。
SREエンジニアの平均年収と評価されるスキル
SREエンジニアの市場価値は非常に高く、企業のインフラ安定稼働と開発スピードの両立を担う重要なポジションです。そのため、SREエンジニアの平均年収はIT業界の中でも高い水準で推移する傾向にあります。
経験年数・スキルレベル別の年収目安
以下の表は、SREエンジニアの経験年数やスキルレベル別の年収レンジを比較したものです。
| スキルレベル | 経験年数の目安 | 想定年収レンジ | 求められる役割・スキル |
|---|---|---|---|
| ジュニアクラス | 1〜3年 | 500万〜700万円 | クラウドインフラの基本操作、監視ツールの運用、手順書に基づく障害対応 |
| ミドルクラス | 3〜5年 | 700万〜1,000万円 | CI/CDパイプラインの構築、IaCを用いた自動化、SLI/SLOの設計 |
| シニア・リード | 5年以上 | 1,000万〜1,500万円以上 | アーキテクチャの全体設計、組織横断的なSRE文化の推進、大規模障害の根本原因解決 |
高年収を実現する技術スタック
SREエンジニアには、AWSやGoogle Cloudなどのパブリッククラウドへの深い理解に加え、DockerやKubernetesを用いたコンテナオーケストレーションの運用スキルが必須です。さらに、GoやPythonといったプログラミング言語の実装力も求められます。
減点方式ではなく加点方式の評価軸
SREの本来の目的は、システムの信頼性を保ちながら新機能のリリース速度を最大化することです。そのため、「どれだけ障害を防いだか」という減点方式ではなく、「エラーバジェットを適切に消費して開発スピードに貢献したか」という加点方式の評価軸を設けることが重要です。
市場価値を高める5つの戦略とキャリアパス
SREエンジニアとして長期的に市場価値を高め、年収アップやキャリアアップを実現するためには、以下の5つの戦略を意識してスキルセットを拡張することが重要です。

1. インフラのコード化(IaC)スキルの徹底
手動でのオペレーションから脱却し、TerraformやAWS CloudFormationを活用してインフラをコードで管理(IaC)するスキルは必須です。これにより、環境構築の再現性を高め、属人化を防ぐことができます。 【具体策】:個人的な開発環境や小規模なプロジェクトから、手動設定を一切やめ、すべてのインフラ構築をTerraform化する実践を積むことが有効です。
2. コンテナ技術とオーケストレーションの習得
Dockerによるコンテナ化と、Kubernetesを用いたオーケストレーションの実務経験は、モダンなシステム環境において極めて高く評価されます。マイクロサービスアーキテクチャの運用には欠かせない技術スタックです。 【具体策】:GCPのGKEやAWSのEKSなど、マネージドなKubernetesサービスに実際に触れ、「CKA(認定Kubernetes管理者)」などの資格取得を目指すことで客観的なスキル証明になります。
3. オブザーバビリティ(可観測性)の高度化
単なる死活監視にとどまらず、DatadogやNew Relicなどを駆使して分散システムの内部状態を把握する「オブザーバビリティ」の知見を深めることが重要です。パフォーマンス低下のボトルネックを素早く特定できる能力は重宝されます。 【具体策】:自社のシステムにOpenTelemetryなどの標準技術を導入し、ログ、メトリクス、トレースを統合して可視化するダッシュボードを自作してみることが第一歩です。
4. プログラミング言語(Go/Python)の習熟
SREは運用の自動化ツールを自ら開発するため、Go言語やPythonの実装力が求められます。特にGo言語は並行処理に強く、クラウドリソースを操作するツールの開発においてデファクトスタンダードになりつつあります。 【具体策】:普段手動で行っているAPIの叩き出しやデータ集計などのトイルを、PythonスクリプトやGoのCLIツールに置き換える社内プロジェクトを自ら立ち上げてみましょう。
5. ビジネス目標と連動したSLO設計のリード
技術的な指標だけでなく、ビジネスのKPIやユーザー体験に直結するSLOを自ら提案・設計できる能力です。開発チームやプロダクトマネージャーを巻き込み、システムの信頼性と開発速度のバランスをとる「非技術的な調整力」がシニアクラスのSREには不可欠です。 【具体策】:まずは担当している1つの機能に対して「ユーザーが快適と感じる基準」を定義し、それをSLIとして計測し始めることから小さくスタートするのが効果的です。
インフラ・バックエンドからのステップアップ
SREエンジニアへのキャリアパスは、インフラエンジニアやバックエンドエンジニアを出発点とするケースが一般的です。上記の5つの戦略とその具体策を一つずつクリアしていくことで、SREへとスムーズにステップアップできます。
テックリードやEMへの道
さらにその先のキャリアとしては、組織全体の技術戦略を牽引するテックリードや、エンジニアリングマネージャー(EM)、VPoEといったマネジメント職への道が開かれています。システム全体を俯瞰し、ビジネス要件と技術的課題の双方を理解する役割を持つため、上流工程や組織マネジメントへの移行がスムーズに行える点が大きな特徴です。
SREエンジニアを組織に導入する際のポイント
SREエンジニアの真価は、組織全体で共通の目標を持つことで発揮されます。
開発チームとの対立を防ぐ合意形成
SREエンジニアを現場で運用する際、開発チームとの対立を防ぐことが最も重要です。運用担当者が単なる「インフラの番人」として孤立してしまうと、本来の目的である開発スピードと信頼性の両立が達成できません。トイルの削減目標を開発チームと共有し、自動化によって浮いた時間を新規開発に投資するサイクルを作ります。
小さく始めるSRE導入ステップ
最初からすべてのシステムにSREのプラクティスを適用するのではなく、影響範囲の小さいサービスから段階的に導入することが推奨されます。初期段階から運用基盤を組み込むことが成功の鍵となります。開発の全体像や技術選定については、SaaS開発とは?費用相場から技術選定、MVP構築の手順まで完全ガイドも参考にしてください。
よくある質問(FAQ)
SREエンジニアに必要なプログラミング言語は何ですか?
インフラの自動化やツールの開発を行うため、PythonやGo言語がよく使われます。また、シェルスクリプトの知識も不可欠です。
インフラエンジニアとの決定的な違いは何ですか?
インフラエンジニアが主に手作業でのサーバー構築・保守を担当するのに対し、SREエンジニアはソフトウェアエンジニアリングの手法を用いて運用を自動化し、信頼性と開発スピードのバランスをデータ(SLI/SLO)に基づいて管理する点が異なります。
まとめ
SREエンジニアは、システムの信頼性向上と開発スピードの両立を実現する、現代のITインフラに不可欠な存在です。本記事では、SREエンジニアの仕事内容、SLI/SLOやエラーバジェットを用いたデータドリブンな運用、DevOpsとの関係性、そして市場価値を高めるキャリアパスについて解説しました。
SREエンジニアとして活躍するには、技術力だけでなく、定量的な指標に基づく判断力や組織を巻き込むコミュニケーション能力が求められます。これらのスキルを継続的に磨き、自動化と継続的な改善サイクルを回すことで、プロダクトのビジネス価値を最大化する中核的な役割を担うことができるでしょう。
この記事を書いた人

タジケン
テクラル合同会社
一部上場企業を経て広告代理店に入社し、デジタルマーケティングの知見を深める。現在はテクラルにて、数千万規模の大型案件でプロジェクトリードを担当。KPI設計や広告運用などのマーケティング領域から、AIを活用したシステム開発の導入支援までプロダクトの成長を一気通貫でサポートしている。本ブログでは、事業フェーズに合わせた実践的なノウハウをお届けする。