【2026年最新】RAG 構築 完全ガイド|自社データ連携AIの作り方と手順
コセケン
テクラル合同会社
自社データ連携AIを実現するRAG 構築の鍵は、データのベクトル化(Embedding)と精度の高い検索エンジンの組み合わせにあります。結論として、実用的なシステムを作るには、GPT-5やClaude 4.7といった最新LLMの特性を理解した上で、適切なデータ前処理と評価サイクルを構築することが重要です。
本記事では、ハルシネーションを抑制し精度を最大化するための「RAGの作り方」を7つの手順で具体的に解説します。技術スタックの選定から前処理、最新のMCP連携、評価指標の設計まで、現場で即活用できる構築方法の全貌を公開します。
手順1:RAG構築の基本アーキテクチャと最適な技術スタックを選定する
自社データに特化したAIシステムを実現するためには、適切なアーキテクチャ設計から始めることが不可欠です。ここでは、RAG構築の第一歩として押さえておくべき基本事項と、実践的な技術スタックの選定について解説します。
RAGシステムの基本構成とアーキテクチャ選定
RAG(Retrieval-Augmented Generation)は、外部のデータベースから関連情報を検索し、その結果をLLM(大規模言語モデル)のプロンプトに組み込んで精度の高い回答を生成させる仕組みです。LLMを単独で利用する場合とRAGを構築する場合の違いについて詳しく知りたい方は、LLMとRAGの違いとは?自社データ活用AI構築の3つの判断基準も併せてご参照ください。
この一連の流れをスムーズに実装するためには、LangChainのようなオーケストレーションツールと、データをベクトル化して保存するベクターストアの組み合わせが重要になります。
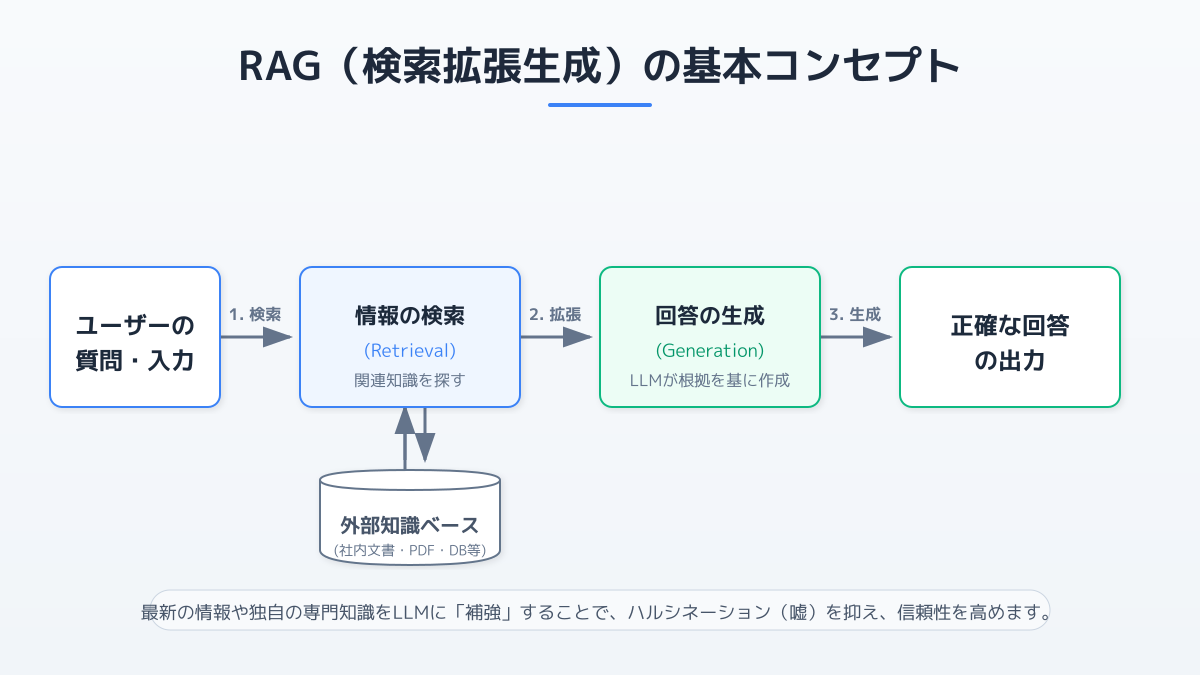
具体的な実装手段として、LangChainとオープンソースのベクターストアであるChromaDBを組み合わせた構成が、標準的なRAG構築の手法として広く採用されています。2026年現在、LangChain RAG開発で失敗しない3つのポイントで解説しているように、最新のMCP(Model Context Protocol)を活用した自律型エージェントとの連携も視野に入れた設計がトレンドとなっています。
手順2:システム構成要素を定義し適切なツールをRAG構築に活用する
RAGを自社システムに導入する際、2つ目の重要な手順となるのが「システムアーキテクチャの設計と適切なツール選定」です。単にLLMとデータベースを繋ぐだけでなく、要件に合わせたコンポーネントを組み合わせることで、初めて実用的なRAG構築が完了します。ここでは、RAGの具体的な作り方から、現場での運用を見据えた判断基準までを整理します。
RAGを構成する基本コンポーネント
実践的なシステムを構築するためには、まず全体像を正確に把握する必要があります。RAGのアーキテクチャは、主に以下の要素で構成されます。
- データソースと前処理: 社内ドキュメントやWebデータを取り込み、LLMが処理しやすいチャンク(意味的な塊)に分割します。
- 埋め込み(Embedding)モデル: テキストデータをベクトル化し、意味的な検索を可能にします。2026年5月時点では、GPT-5.5のEmbedding APIや最新のオープンソースモデルが高い精度を誇ります。
- ベクターストア: ベクトル化されたデータを保存し、高速な類似度検索を実行するデータベースです。
- オーケストレーションフレームワーク: これらの要素とLLMを連携させ、一連の処理フローを制御します。
手順3:データ前処理とチャンク化のプロセスを最適化して精度を上げる
RAGをシステムとして実装する際、どのようなフレームワークやデータベースを選定し、どう連携させるかがプロジェクトの成否を分けます。特に、精度の高いRAG構築を実現するためには、データの前処理プロセスが極めて重要です。
データ前処理における判断ポイント
システムを構築する過程で最も重要な判断ポイントとなるのが、多様な社内データの前処理プロセスです。企業が保有するデータは、プレーンテキストだけでなく、PDF、Wordファイル、社内WikiのHTML、さらには画像を含むスライド資料など多岐にわたります。
これらの非構造化データをそのままベクターストアに投入しても、高い検索精度は得られません。そのため、どのデータをどのような単位で分割(チャンク化)するかという設計が必須です。たとえば、マニュアルなどの長文ドキュメントであれば、意味のまとまりごとに分割するセマンティックチャンキングを採用するか、あるいは固定文字数で機械的に分割するかを、対象データの特性に合わせて判断する必要があります。
手順4:ベクターストアの選定とスケーラビリティを設計してRAG構築の土台を作る
RAG構築において、検索精度とシステム全体のパフォーマンスを大きく左右するのがベクターストア(ベクトルデータベース)の選定と実装アプローチです。ここでは、自社データ連携の基盤となるベクターストアに関する基本事項と、プロジェクトのフェーズに応じた判断ポイントを整理します。
ベクターストア選定の基本事項と判断ポイント
システム構築の要となるベクターストアは、テキストデータを数値化(ベクトル化)して保存し、ユーザーからの質問と意味的に近い情報を高速に検索する役割を担います。現場での判断ポイントは、対象となるデータ規模、将来的なスケーラビリティ、およびインフラの運用コストのバランスをどのように取るかという点に尽きます。
手順5:検索精度の評価指標を設定しRAG構築後の改善サイクルを確立する
RAGシステムを実業務に導入する上で、適切なフレームワークの選定と、構築後の継続的な評価・改善サイクルを回すことが成功の鍵となります。ここでは、実践的なRAG構築における評価手法と、運用フェーズにおける判断ポイントについて整理します。
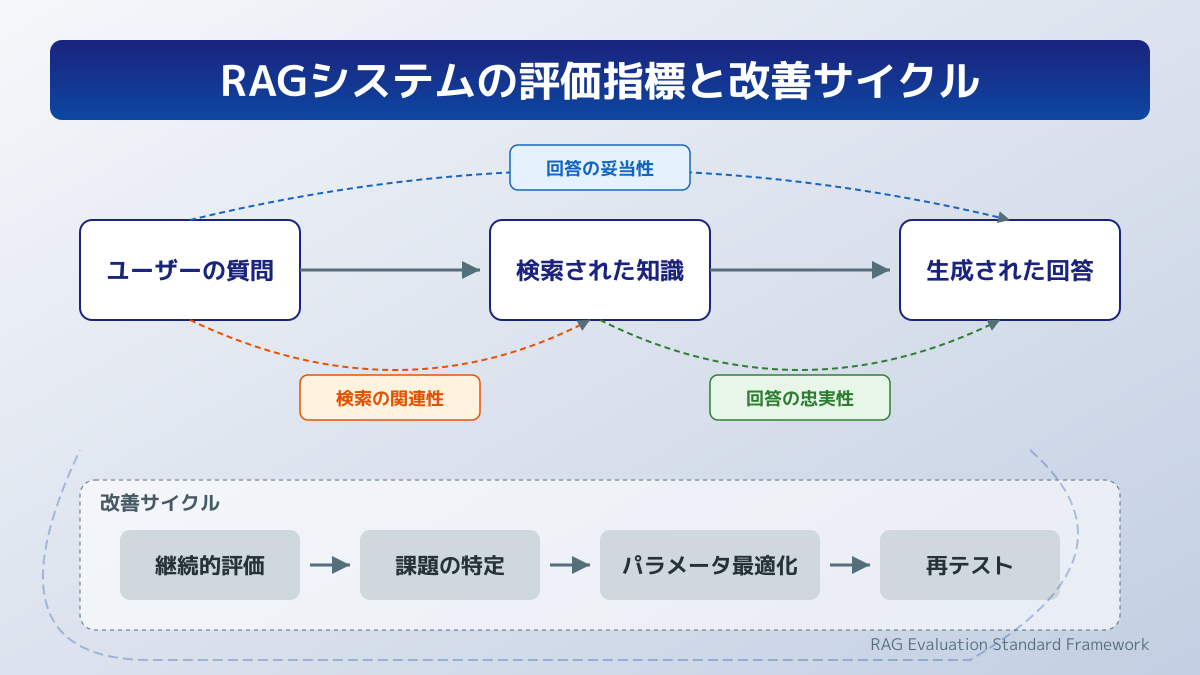
RAGシステムの評価指標と改善サイクル
システムが組み上がった後、それが実用レベルに達しているかを客観的に判断するための指標設計が不可欠です。RAGシステムの品質は、主に検索の精度と生成の精度の2つの観点から評価します。
手順6:セキュリティ対策とデータガバナンスを実装してセキュアなRAG構築を実現する
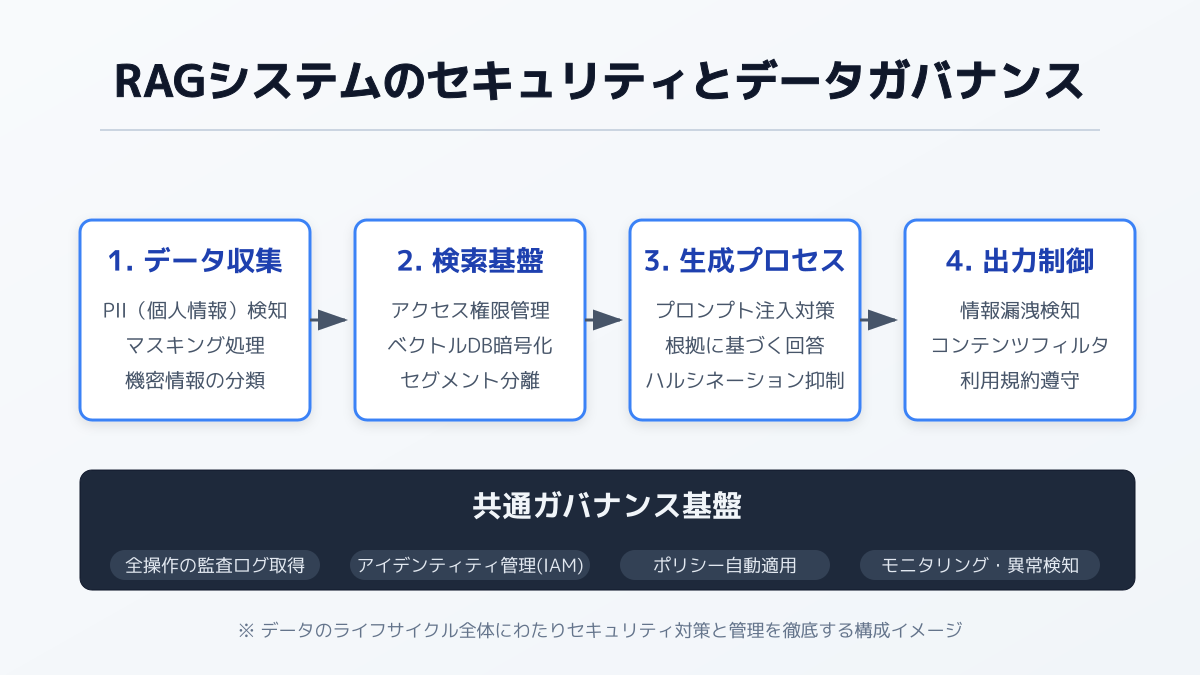
RAGシステムを企業に導入する際、自社データの機密性をいかに担保するかが極めて重要になります。ここでは、セキュリティ対策とデータガバナンスの観点からRAG構築のポイントを整理します。
オープンソースを活用したセキュアな構築の基本
企業が保有する機密データや顧客情報を扱う場合、外部のAPIへデータを送信することにセキュリティ上の懸念を抱くケースは少なくありません。そのため、クローズドな環境で完結するRAG構築方法を採用することが、最初の基本事項となります。
手順7:MVP開発から本番運用へ段階的に移行しRAG構築を成功させる
RAGシステムを実用化するうえで欠かせないのが、適切なフレームワークとベクターストアの選定です。ここでは、実践的な実装アプローチという観点から、段階的なRAG構築の基本事項を整理します。
フレームワークとベクターストアの選定基準
開発を効率化するには、既存のツール群を組み合わせる判断が重要です。自社の要件に合わせて、オープンソース技術を採用するか、マネージドサービスを利用するかの判断ポイントを明確にしてください。初期段階ではDifyを用いたRAGの作り方のように、ノーコードツールを利用して手軽にプロトタイプを作成し、要件が固まってきた段階で本番環境に適した技術スタックへ移行するのが定石です。
現場運用における注意点と要点
現場でRAGシステムを運用する際は、継続的なデータ更新と検索精度の維持が課題となります。社内データは日々変化するため、インデックスの自動更新パイプラインを設計することが不可欠です。また、手軽に試せるツールでMVP検証を行った後、本番環境のトラフィックに耐えうるスケーラブルな構成へ移行する計画を立てておきましょう。
技術スタックの選定から運用を見据えた設計までを一貫して行うことが、RAG構築プロジェクトを成功に導く要点です。
よくある質問(FAQ)
RAG構築の費用はどれくらいかかりますか?
初期費用を抑えるなら、ChromaDBやQdrantなどのオープンソース版を活用し、自社インフラや安価なクラウドインスタンスで運用する方法があります。一方、Pineconeなどのフルマネージドサービスを利用する場合、データ量や検索回数に応じた従量課金が発生しますが、インフラ管理コストを削減できます。
プログラミング未経験でもRAGの作り方は学べますか?
Difyなどのノーコード・ローコードプラットフォームを活用すれば、詳細なプログラミングなしでもRAGの作り方を学び、実際に動作するプロトタイプを構築することが可能です。ただし、本番運用における高度な精度改善には、PythonやLangChainの知識が必要になるケースが多いです。
RAG構築とファインチューニングの違いは何ですか?
RAGは外部データを「検索」して回答に含める手法で、情報の更新が容易でハルシネーションを抑制しやすいのが特徴です。一方、ファインチューニングはモデル自体に知識を「学習」させる手法で、専門的な文体や特定のタスクへの適応に向いていますが、再学習のコストが高く情報の更新が難しいという側面があります。
まとめ
本記事では、自社データとLLMを連携させるRAG構築方法について、7つの具体的な手順を解説しました。構築を成功させるためには、以下の要素が不可欠です。
- 適切なアーキテクチャ設計: LLMオーケストレーションとベクターストアの組み合わせが基盤となります。
- ツール選定: フレームワークを効果的に活用し、コストとスケーラビリティのバランスを取ります。
- ベクターストアの最適化: データ規模や運用要件に応じた選定が重要です。
- 継続的な評価と改善: 検索精度と生成の正確性を評価し、運用パイプラインを確立します。
- セキュリティとデータガバナンス: 機密データの保護とライフサイクル管理を徹底します。
これらの手順に従い、段階的なアプローチでMVPを構築し、検証と改善を繰り返すことが、実業務で価値を生み出すRAG構築を実現する鍵となるでしょう。
RAG構築から運用フェーズへ移行する際は、本記事で整理した判断基準を順に確認してください。
この記事を書いた人

コセケン
テクラル合同会社
スタートアップでのCTO経験を経て、現在はテクラル合同会社にてシステム開発全般を牽引しています。アプリおよびWebの開発から、バックエンド、インフラ構築に至るまで幅広い技術領域に対応可能です。スピード感を持った品質の高いシステム開発を得意としており、新規プロダクトの立ち上げを一気通貫で支援します。本ブログでは実践的な開発ノウハウを発信していきます。