LLMとRAGの違いとは?自社データ活用AI構築の3つの判断基準
タジケン
テクラル合同会社

LLMとRAGの違いは、一言で言えば「答えを生成するときに参照する知識の出どころ」にあります。LLM(大規模言語モデル)は事前学習した汎用知識だけを使って回答し、RAG(検索拡張生成)は外部データベースをその場で検索し、自社固有の最新データに基づいて回答します。一般的な文章作成や要約ならLLM単体で十分ですが、社内規定や製品情報など自社データに沿った正確な回答が必要なら、RAGを組み合わせるのが基本方針です。
まず、両者の違いを早見表で整理します。
| 観点 | LLM単体 | RAG(検索拡張生成) |
|---|---|---|
| 知識の源泉 | 事前学習した汎用データ | 外部データベース(自社データ) |
| 最新情報への対応 | 学習時点まで(更新に再学習が必要) | データを差し替えれば即反映 |
| 自社固有データ | 基本的に未対応 | 対応できる(中核の用途) |
| ハルシネーション | 起きやすい | 参照元を示して抑制できる |
| 回答の根拠提示 | 難しい | 出典を明示できる |
| 向くタスク | 文章作成・要約・アイデア出し | 社内QA・カスタマーサポート・ナレッジ検索 |
結論として、「汎用的な知識で足りる」ならLLM単体、「自社の独自データに基づく正確な応答が必要」ならRAGを選びます。本記事では、この選択を左右する仕組みの違いを整理したうえで、自社データを活用したAIを構築する際の3つの判断基準を具体的に解説します。
LLMとRAGの仕組みの違い
LLMとRAGの仕組みの違いは、「学習済みの知識だけで答えるか」「外部データを検索してから答えるか」という処理の流れにあります。下の図のように、RAGはLLMの前段に検索のステップを挟む構成です。
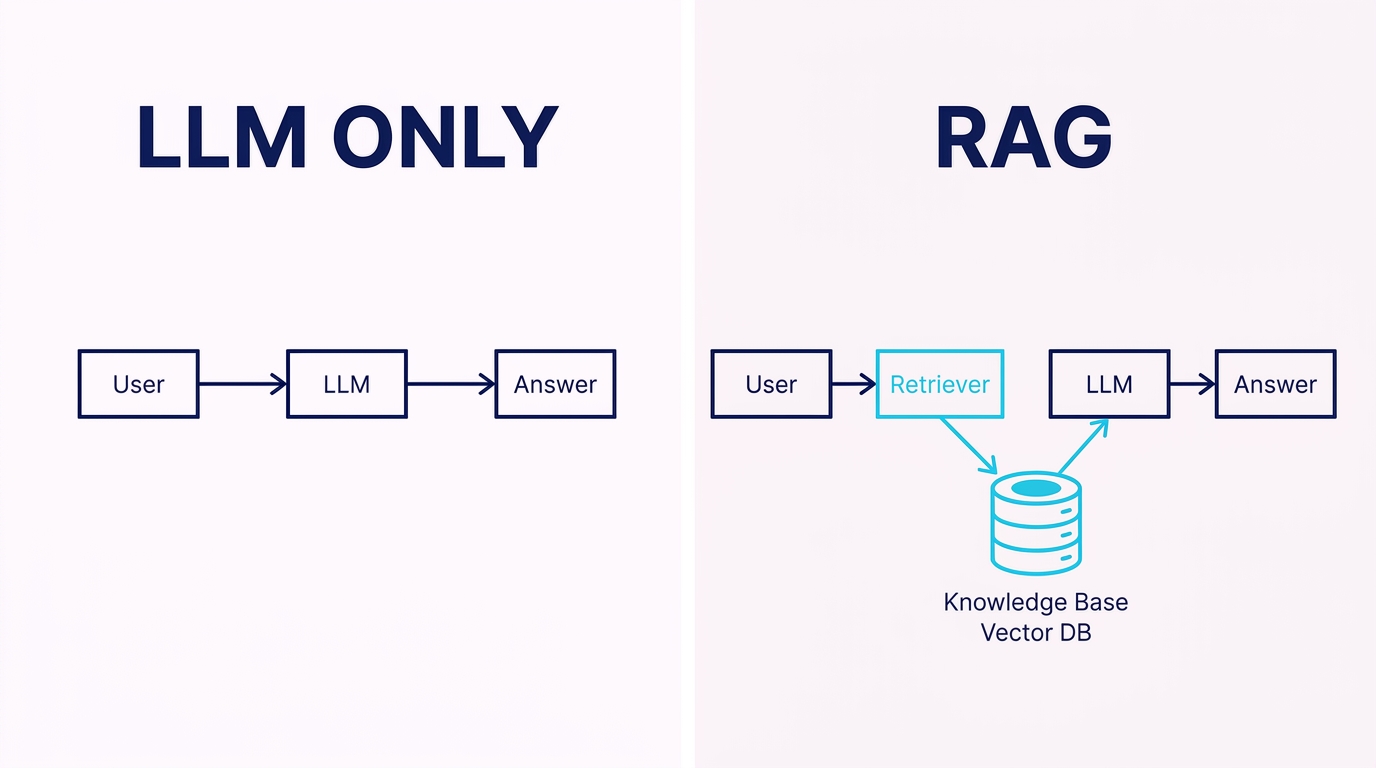
LLM単体では、AIは事前に学習した知識だけを基に回答を出力します。文章作成やアイデア出し、汎用的なコード生成といったタスクであれば、これだけで十分な品質が得られます。一方で、学習データに含まれない最新ニュースや社内固有の規定については、正確に答えられません。
RAGは、Retrieval-Augmented Generation(検索拡張生成)の略で、検索(Retrieval)と生成(Generation)を組み合わせた技術です。処理は次の流れで進みます。
- ユーザーの質問を受け取る
- 質問に関連する文書を外部データベース(多くはベクトルデータベース)から検索する
- 検索で得た情報を質問と一緒にプロンプトへ組み込む
- その情報を踏まえてLLMが回答を生成する
検索の中心となるのが、文書を数値ベクトルに変換して意味の近さで探す「ベクトル検索」です。これにより、キーワードが完全一致しなくても、質問の意図に近い社内文書を引き当てられます。モデル自体を再学習させずに、データベースを更新するだけで最新の自社データを反映できる点が、RAGの本質的な特徴です。
両者の出力の違いを、社内の経費精算ルールに関する質問で比較してみます。
- LLM単体:「経費精算の一般的な手順として……」と汎用的な知識を返すか、自社固有のルールについてもっともらしい誤り(ハルシネーション)を出力するリスクがあります。
- RAG:社内規定のデータベースを検索し、「2026年4月の改定により、1万円以上の接待交際費には事前申請が必須です(参照:経費規定_最新版.pdf)」と、根拠つきで正確に回答します。
この仕組みの違いを押さえると、「汎用知識の要約で足りるのか」「自社の独自データに基づく応答が必要なのか」という観点で、過剰な開発投資を避けながら目的に合うシステムを設計できます。LLMをクラウドに送らず自社環境で動かす選択肢を検討する場合は、ローカルLLM 日本語モデル完全ガイド【2026年版】|企業向け環境構築と主要ツール比較 も判断材料になります。
自社データ活用AIを構築する3つの判断基準
自社データを活用するAIをLLM単体で組むかRAGで組むかは、「情報の鮮度」「ハルシネーション許容度」「運用コスト」の3点で判断します。技術的な優劣ではなく、解きたい業務課題に合わせて選ぶのがポイントです。順に見ていきます。
判断基準1:情報の鮮度と更新頻度
参照する情報が頻繁に変わるなら、RAGが適しています。社内マニュアル・製品情報・価格表のように更新が前提のデータは、LLM単体だと反映のたびに再学習が必要になり、現実的ではありません。
RAGなら、参照元のPDFやテキストを最新版に差し替えるだけで回答内容が即座に更新されます。社内ヘルプデスクや製品サポートのように「事実に基づく最新の回答」が価値を左右する用途では、この更新のしやすさが決定的な差になります。逆に、情報がほとんど変わらず汎用知識で足りる用途なら、LLM単体でも問題ありません。
判断基準2:ハルシネーションの許容度と根拠提示の必要性
誤答が業務上のリスクになる領域では、参照元を明示できるRAGを選びます。LLM単体は学習済みの知識から推測で回答するため、社内の最新情報や未公開データについては、事実と異なる回答(ハルシネーション)を生成することがあります。
RAGは、検索で取得した文書を根拠として回答に紐づけられるため、「どの資料を根拠にしたか」を提示できます。これは、金融・法務・医療や、社内規定にもとづく判断を扱うシステムで特に重要です。ただし、RAGの精度は参照する社内データの品質に依存します。古い情報や表記揺れが残ったままだと、AIも誤った回答を出すため、導入前のデータクレンジング(ドキュメントの最新化・表記統一・不要データの削除)が前提になります。
判断基準3:運用コストとメンテナンス体制
長期運用の保守工数まで含めて考えると、情報更新が多い用途ではRAGがコスト面でも有利です。LLM単体で新しい情報を反映するには、モデルの再学習(ファインチューニング)が必要で、計算リソースと専門人材を要し、更新のたびにコストがかさみます。
RAGは、回答時に外部データベースを参照するため、データを差し替えるだけで内容を更新でき、再学習が不要です。一方で、参照元のデータガバナンスは欠かせません。古いマニュアルや重複ドキュメントを放置すると、AIが誤った情報を抽出します。定期的なドキュメントの棚卸しや、不要データをアーカイブする仕組みを運用体制に組み込むことが、精度を保つ前提です。AIシステムを安定して運用し続けるための観点は、LLMOpsとは?生成AIシステムを安定運用する6つのポイント|企業向け完全ガイド で整理しています。
RAGとファインチューニングの違い
自社データ活用というテーマでは、RAGとファインチューニングが混同されがちですが、両者は役割が異なります。RAGが「外部の知識を検索して参照させる」手法なのに対し、ファインチューニングは「モデル内部の振る舞いそのものを追加学習で変える」手法です。
| 観点 | RAG | ファインチューニング |
|---|---|---|
| 変えるもの | 参照する外部知識 | モデル内部の重み・振る舞い |
| 知識の更新 | データ差し替えで即時 | 再学習が必要 |
| 得意なこと | 最新・固有データへの対応、根拠提示 | 出力の文体・形式・タスク特化 |
| 主なコスト | データ整備・検索基盤の構築 | 学習データ作成・計算リソース |
実務では、まずプロンプトの工夫で対応できるかを検証し、外部知識の参照が必要ならRAG、出力フォーマットや専門的な振る舞いをモデルに定着させたい場合にファインチューニングを検討する、という段階的なアプローチが一般的です。両者は排他ではなく、RAGで最新の知識を参照させつつ、ファインチューニングで出力形式を整えるといった併用も有効です。
よくある質問
LLMとRAGのどちらを選ぶべきですか?
一般的な文章作成や要約、アイデア出しなど、普遍的な知識で対応できるタスクならLLM単体で十分です。社内規定や最新の製品情報など、自社固有のデータに基づく正確な回答が必要な場合は、ハルシネーションを抑えるためにRAGの導入を推奨します。
RAGの導入にはどのような準備が必要ですか?
RAGの回答精度は参照データの品質に依存するため、事前のデータ整備が欠かせません。社内ドキュメントの最新化、表記揺れの統一、不要データの削除といったデータクレンジングを行い、AIが検索しやすい状態を整える必要があります。
RAGを導入すれば再学習は一切不要ですか?
外部データの更新に関しては再学習なしで対応できます。ただし、モデルの推論能力や特定の出力フォーマットへの適応を高めたい場合は、ファインチューニングを併用するアプローチが有効なケースもあります。
LLMとRAGは組み合わせて使えますか?
はい。RAGはLLMを前提とした技術で、内部でLLMが回答生成を担います。検索で取得した情報をLLMに渡すことで、汎用的な文章生成能力と自社データへの対応力を両立させます。近年は、LLM自身が検索の要否や検索クエリを判断する「Agentic RAG」のように、より自律的に外部情報を扱う構成も広がっています。
まとめ:自社の課題に合わせて構成を選ぶ
LLMとRAGは、回答に使う知識の源泉と更新方法が根本的に異なります。LLM単体は汎用知識に強い一方、最新情報や自社固有データへの対応、ハルシネーション対策には限界があります。RAGは外部データベースをリアルタイムに参照することで、これらの課題を解決します。
自社データを活用するAIを設計する際は、次の3点で判断するのが実務的です。
- 情報の鮮度:更新頻度が高いデータを扱うならRAG
- ハルシネーション許容度:根拠提示や正確性が必須ならRAG
- 運用コスト:再学習の負荷を避けたい長期運用ならRAG
重要なのは、技術の優劣で選ぶのではなく、解きたい業務課題とデータの特性から逆算して構成を決めることです。多くの場合、汎用的なやり取りはLLM単体で、自社データに基づく正確な応答はRAGで、と役割を分けて組み合わせる設計が現実的な落としどころになります。自社のどの業務にどちらが必要かを見極めることが、過不足のないAIシステムを構築する出発点です。
この記事を書いた人

タジケン
テクラル合同会社
一部上場企業を経て広告代理店に入社し、デジタルマーケティングの知見を深める。現在はテクラルにて、数千万規模の大型案件でプロジェクトリードを担当。KPI設計や広告運用などのマーケティング領域から、AIを活用したシステム開発の導入支援までプロダクトの成長を一気通貫でサポートしている。本ブログでは、事業フェーズに合わせた実践的なノウハウをお届けする。