LangChain RAG開発で失敗しない3つのポイント|MCP連携とAgent実装の実践ガイド
コセケン
テクラル合同会社

LangChain RAGでハルシネーションを抑制し、実用的なAIシステムを構築する最大のポイントは、データの前処理、MCP連携によるエージェントの自律化、そして運用後の継続的な精度評価の3点です。本記事では、これら3つのフェーズにおける具体的な実装ノウハウと検証手順を解説します。
大規模言語モデル(LLM)を活用したAIシステム開発において、企業独自のデータを正確に反映させることは喫緊の課題です。特に、LangChain RAG(Retrieval-Augmented Generation)の構築では、多岐にわたる専門知識が求められます。
最初から大規模で完璧なシステムを目指すのではなく、まずは主要な機能や特定のデータセットに絞って検証を始めることが推奨されます。AIを活用した新規事業や社内システム立ち上げの具体的なアプローチについては、MVP開発の進め方と検証ポイントを参考に、小さく始めて改善を繰り返すアジャイルなサイクルを回してみてください。また、基盤となるフレームワークの基礎知識については、LangChainとは?LLMアプリ開発を加速する基本機能で詳しく解説しています。あわせて、AIエージェントの自律的な仕組みについては、AIエージェントとは?自律型AIの仕組みとビジネス活用も参考にしてください。
さらに、RAGとAIエージェントの違いを正しく把握することが、要件に適したシステム設計の第一歩です。実務での使い分けについては、RAGとAIエージェントの実践入門|違いから連携までで詳しく比較しています。
データソースの選定とチャンク戦略
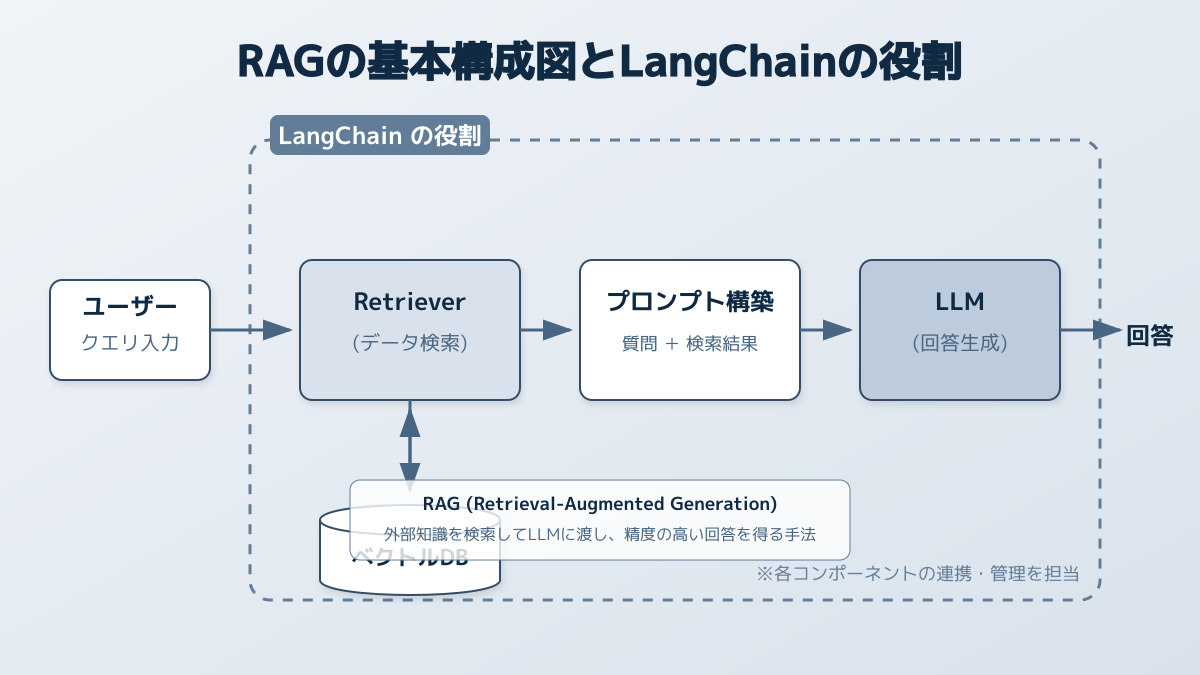
LangChainを用いたRAGを構築する際、最初の重要なステップとなるのがデータソースの選定と前処理の最適化です。企業独自のデータを取り込んで回答精度を高めるLangChain RAGの基盤は、入力されるデータの質と構造に大きく依存します。
データ前処理の最適化
システムに読み込ませるドキュメントは、そのままではAIが適切に検索・理解できません。社内規程のような構造化された文書と、議事録のような非構造化データでは、処理方法を柔軟に変える必要があります。
例えば、パナソニック コネクトでは「ConnectAI」の導入により、全社員が安全に社内ナレッジへアクセスできる環境を構築し、年間約44.8万時間の削減という成果を上げています(出典:パナソニック ホールディングス ニュースリリース 2025年7月7日公表 https://news.panasonic.com/jp/press/jn250707-2 )。こうした成功の裏には、膨大なドキュメントのクレンジングと適切なメタデータ付与という徹底した前処理があります。
表や図解を含む複雑なドキュメントの解析では、単純なテキスト抽出ではレイアウト情報が崩れるため、専門のパーサーを組み合わせて前処理の精度を高める必要があります。AIを活用した新規サービスを企画する段階から、こうした技術的ハードルを想定しておくことが不可欠です。具体的な検証の進め方については、新規事業立ち上げのプロセスと成功手法も合わせてご確認ください。
チャンク分割とメタデータの活用
長文のPDFや社内マニュアルを意味の通る適切なサイズに分割するチャンク(Chunking)戦略が、回答精度の向上に直結します。ここでの判断ポイントは、チャンクサイズ(文字数)とオーバーラップ(重複部分)のバランスです。
チャンクが大きすぎると回答に関係のないノイズが混じり、LLMのトークン制限を超過するリスクがあります。逆に小さすぎると前後の文脈が失われてしまいます。また、分割したテキストに対して「作成日」や「部署名」といったメタデータを付与することで、検索時にノイズを減らし、より的確な情報を抽出できるようになります。
MCP連携とAIエージェントの自律化
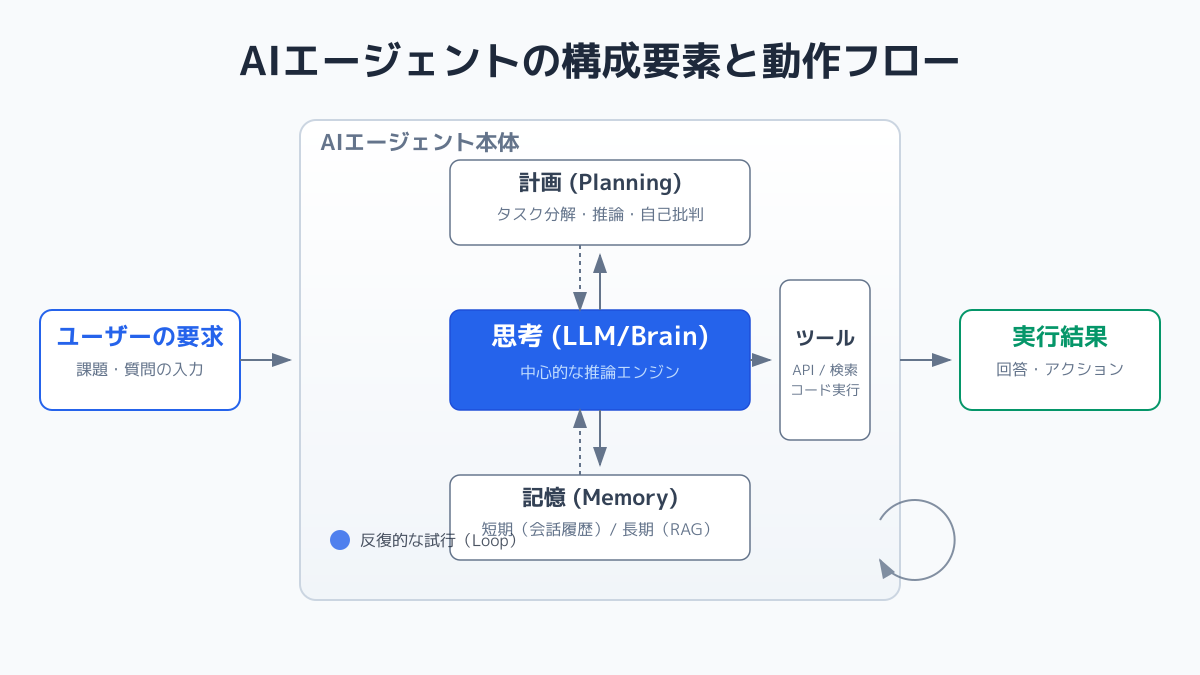
単なる一問一答の検索を超え、複雑なビジネス課題に対処するためには、外部ツールとの統合による高度なプロンプト制御と、AIエージェントの自律化が求められます。
MCPによるプロンプト制御と動的分岐
LangChain MCP(Multi-Chain Prompting / Model Context Protocol)を活用することで、複数のプロンプトチェーンを組み合わせた複雑なタスク処理が可能になります。単純なベクトル検索で終わらせず、検索結果に基づいて次のアクションをどう分岐させるかが重要な判断ポイントです。
取得した情報が不十分な場合には再度別のデータベースへ検索をかけるなど、動的なチェーン設計を取り入れることで、回答の精度と網羅性が劇的に向上します。外部ツールとの具体的な連携手法については、DifyとMCP連携で何ができる?AIエージェント構築と業務自動化ガイドでも詳しく紹介しています。
LangChain Agentによる自律的なツール操作
LangChain Agentを組み込むことで、LLM自身が「どのデータベースを検索すべきか」「どのようなツールを実行すべきか」を自律的に判断できるようになります。ユーザーの曖昧な質問に対しても、複数回の検索や外部APIの呼び出しを組み合わせた精度の高い回答生成が可能です。
例えば、「最新の売上データを取得し、目標未達の営業担当者にSlackで通知して」という指示に対して、LangChain Agentは自律的にタスクを実行します。さらに詳しいコード例や実装手順は、Pythonで実践するAIエージェントの作り方を確認してください。
エージェント化を進める際の判断ポイントは、タスクの複雑さと処理速度のバランスです。すべてのクエリをエージェントに処理させると、推論回数が増加して応答速度が低下するリスクがあります。
運用フェーズの精度評価と継続的改善
システムをリリースして終わりではなく、実際のユーザーのクエリに対して適切な回答が生成されているかを常に監視する仕組みが不可欠です。本番環境移行後の継続的な改善サイクルが、AIシステムの価値を決定づけます。
検索と生成の分離評価
回答の精度低下が「検索(Retriever)の失敗」によるものか、「生成(LLM)の失敗」によるものかを正確に切り分けることが重要です。ユーザーが求めている情報がベクトルデータベースから正しく抽出されているか、そしてLLMがハルシネーションを起こしていないかを個別に検証します。
ノーコードツールを活用したRAG構築についても、Difyを用いたRAG AIエージェントの作り方で評価と改善のポイントを解説していますので、参考にしてください。
データの鮮度維持とモニタリング
運用時の注意点として、参照元ドキュメントの更新管理が挙げられます。ベクトルデータベース内の情報が陳腐化すると、LangChain RAGの信頼性が著しく低下します。情報の変更に合わせて、インデックスを自動で再構築するデータパイプラインの整備が不可欠です。
ユーザーからのフィードバックを収集し、プロンプトの微調整やチャンク分割の最適化へ継続的に反映させるサイクルを回すことが、システムを長期的にビジネスで成功させる要点です。
まとめ
本記事では、LangChainを用いたRAGシステムを高度化し、実用的なAIエージェントを開発するための重要ポイントを解説しました。
特に以下の点が、ビジネス課題を解決する堅牢なシステム構築の鍵となります。
- データソースの最適化とチャンク戦略: パナソニック コネクトの事例にもある通り、高品質なデータ前処理と適切なチャンク分割が、検索精度を大きく左右します。
- MCP連携とプロンプト制御: LangChain MCPを用いて複数のプロンプトチェーンを組み合わせることで、複雑なタスク処理と動的な判断ロジックを実現します。
- AIエージェントの自律化: LangChain Agent機能を活用し、外部ツール連携や自律的な思考プロセスを組み込むことで、より高度な問題解決能力を持たせます。
- 継続的な精度評価と改善: 運用フェーズでのパフォーマンス監視とフィードバックループが、システムを成長させる上で不可欠です。
これらの要点を踏まえ、AIシステムの構築は一度きりの開発ではなく、継続的な改善サイクルを通じて進化させるべきものです。本記事で得た知見を活かし、貴社のビジネスに貢献するAIエージェント開発を推進してください。
この記事を書いた人

コセケン
テクラル合同会社
スタートアップでのCTO経験を経て、現在はテクラル合同会社にてシステム開発全般を牽引しています。アプリおよびWebの開発から、バックエンド、インフラ構築に至るまで幅広い技術領域に対応可能です。スピード感を持った品質の高いシステム開発を得意としており、新規プロダクトの立ち上げを一気通貫で支援します。本ブログでは実践的な開発ノウハウを発信していきます。


