マイクロサービスアーキテクチャ成功の8原則!設計・API連携・運用を徹底解説
コセケン
テクラル合同会社

マイクロサービスアーキテクチャでシステム開発を成功させる最大の鍵は、技術的な分割だけでなく「ビジネス要件に基づいたドメイン分割」と「組織体制の最適化」を両立させることです。単にシステムを細分化するだけでは、通信遅延や運用負荷の増大という新たな課題を生み出します。本記事では、サービス分割の基準からマイクロサービスパターンの選定、マイクロサービスAPIの連携、データ一貫性の管理まで、複雑な分散システムを堅牢に構築するための8つの原則を具体的に解説します。
原則1:ビジネスドメインに基づくサービス分割
マイクロサービスアーキテクチャを成功させる上で、最初に直面する最も重要な課題は「サービスの分割境界をどのように設計するか」です。システムを小さく分割すればするほど良いわけではなく、ビジネス上の意味を持つ単位で適切に切り分ける必要があります。
サービスの分割単位と境界の設計
マイクロサービスアーキテクチャの基本は、巨大で複雑なシステム(モノリス)を、独立してデプロイ可能な小さなサービスの集合体へと再構築することです。各サービスは特定のビジネス機能に特化し、APIを通じて互いに連携します。
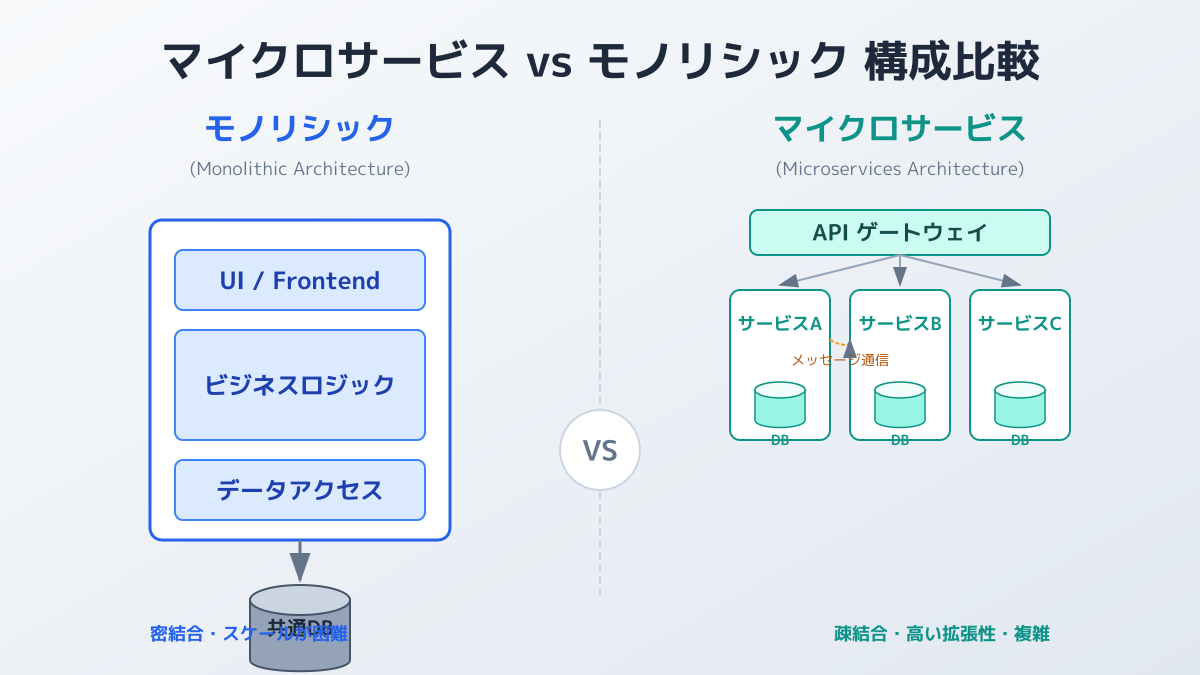
サービスを分割する際の明確な判断基準は、ドメイン駆動設計(DDD)における「境界づけられたコンテキスト」に基づいているかどうかです。たとえば、ECサイトを構築する場合、「商品管理」「注文処理」「ユーザー管理」といったビジネス上の関心事ごとにサービスを分割します。データベースのテーブル単位や、単なる機能のまとまりで分割してしまうと、サービス間の依存関係が強くなり、結果的に「分散モノリス」と呼ばれる運用困難なシステムに陥ります。
導入タイミングと判断の基準
すべてのプロジェクトにマイクロサービスアーキテクチャが適しているわけではありません。特に新規事業の立ち上げフェーズでは、導入のタイミングを慎重に見極める必要があります。
プロダクトの仕様が頻繁に変わる初期段階でサービスを細かく分割すると、仕様変更のたびに複数のサービスにまたがる改修が発生し、開発スピードが著しく低下します。そのため、まずはシンプルなモノリシックアーキテクチャで素早く市場の反応を確かめ、ユーザー数や開発組織の規模が拡大したタイミングで段階的にマイクロサービスへ移行するアプローチが確実です。初期フェーズにおける具体的な検証手法については、MVP開発の進め方と検証ポイント を参考にしてください。
段階的移行を実現するストラングラーフィグパターン
導入タイミングを見極めた後、実際にモノリスからサービスを切り出す局面では、システム全体を一度に作り直す「ビッグバン・アプローチ」を避け、既存システムを稼働させたまま特定の機能だけを少しずつ新しいサービスへ置き換えていく「ストラングラーフィグパターン(Strangler Fig Pattern)」が有効です。開発期間の長期化やリリース時の障害リスクを抑えながら、段階的にアーキテクチャを進化させられます。
切り出す機能の優先順位は、「変更頻度が高いか」「個別のスケーリングが必要か」という基準で判断します。たとえばECサイトであれば、トラフィックが集中しやすく他のコア業務(注文や決済)からも比較的切り離しやすい「商品検索機能」や「レコメンド機能」から独立させることで、スケーラビリティ向上の恩恵を早期に実感でき、開発チームの移行への習熟度も高められます。
運用面では、モノリスと新しいマイクロサービスが同じデータベースを直接参照する状態を避け、それぞれが独自のデータストアを持つよう設計することが前提になります。また、ユーザーからのリクエストを新旧どちらのシステムに振り分けるかを制御するAPIゲートウェイのルーティング設定に加え、新しいサービスに不具合が生じた場合に即座に旧システムへ切り戻せるフェイルオーバーの仕組みを用意しておくことが、移行期間中の安全網となります。
現場で運用する際の注意点
実際に現場でマイクロサービスを運用する際は、分散システム特有の複雑さに対処しなければなりません。特に注意すべき点は以下の3つです。
- 通信レイテンシの増加 サービス間の通信がネットワーク越しになるため、モノリス内の関数呼び出しと比較して応答遅延が発生します。同期的なAPI連携を多用せず、非同期メッセージングを活用して結合度を下げる設計が求められます。
- データ整合性の担保 各サービスが独立したデータベースを持つため、システム全体でのトランザクション管理が困難になります。結果整合性(Eventual Consistency)を許容するビジネスプロセスへの見直しが必要です。
- 運用監視の複雑化 障害発生時に「どのサービスのどこでエラーが起きたのか」を特定することが難しくなります。分散トレーシングや統合ログ管理の仕組みを初期段階から導入することが不可欠です。
サービス分割の要点を整理すると、「ビジネスドメインに沿った適切な境界設計を行うこと」「初期段階での過度な分割を避け、組織とプロダクトの成長に合わせて導入すること」に尽きます。技術的な理想を追求するのではなく、ビジネスの俊敏性を高めるための手段としてアーキテクチャを選択することが重要です。
原則2:過度な細分化を防ぐ境界設計
マイクロサービスアーキテクチャを成功に導くための第2の原則は、ビジネス要件に基づいた「サービス境界の適切な分割」です。システムを単に技術的な層(UI、ビジネスロジック、データベースなど)で切り離すのではなく、ビジネス上の 機能やドメインごとに独立 させる必要があります。

サービス分割の粒度
サービスをどの粒度で分割すべきかは、多くのプロジェクトで議論の的となります。この判断基準を具体化する上で有効なのが、ドメイン駆動設計(DDD)における 境界付けられたコンテキスト という考え方です。
例えば、ECサイトを構築する場合、「注文」「在庫」「決済」といったビジネス機能ごとにサービスを分割します。それぞれのサービスが独自のデータベースを持ち、他のサービスに依存することなく独立してデプロイやスケールアップができる状態になっているかが、正しい分割かどうかの重要な指標です。機能の追加や改修が発生した際、影響範囲が1つのサービス内に収まるのであれば、その境界設計は適切に機能していると判断できます。
細分化リスクと適切なアプローチ
現場で運用する際の注意点として「過度な細分化」が挙げられます。サービスを小さく分割しすぎると、サービス間のネットワーク通信が急増し、システム全体のパフォーマンス低下や遅延を招くリスクがあります。また、複数のサービスにまたがるデータ整合性を担保するための分散トランザクション処理が複雑化し、かえって開発・運用コストが増大してしまいます。
したがって、境界設計の要点として押さえておくべきは、 小さくすること自体を目的化しない ことです。まずはやや大きめの粒度からスタートし、トラフィックの増加やチーム体制の拡大に合わせて徐々に分割していくアプローチが安全です。
特にプロダクトの初期フェーズでは、アーキテクチャの複雑さが仮説検証のスピードを落とす原因にもなります。事業の初期フェーズにおける最適な進め方については、新規事業立ち上げのプロセスと成功のポイント も併せて参考にしてください。ビジネスの成長スピードとシステムの複雑さのバランスを見極めることが、運用を軌道に乗せる鍵となります。
原則3:課題に合わせたマイクロサービスパターンの選定
マイクロサービスアーキテクチャを成功に導くための3つ目の原則は、システム要件に応じた適切なマイクロサービスパターンの選定と、それに伴うAPI連携やデータ整合性の設計です。モノリシックなシステムからサービスを分割すると、ネットワーク越しに複数のサービスが通信し合う分散システム特有の課題が発生します。ここでは、現場で直面する技術的課題を解決し、ビジネスの俊敏性を高めるための具体的なアーキテクチャ設計について解説します。
主要なパターンの種類
マイクロサービスアーキテクチャでは、各サービスが独立して稼働するため、クライアントからのリクエスト処理やサービス間のデータ同期をどのように扱うかが重要になります。代表的なマイクロサービスパターンには、以下のようなものがあります。
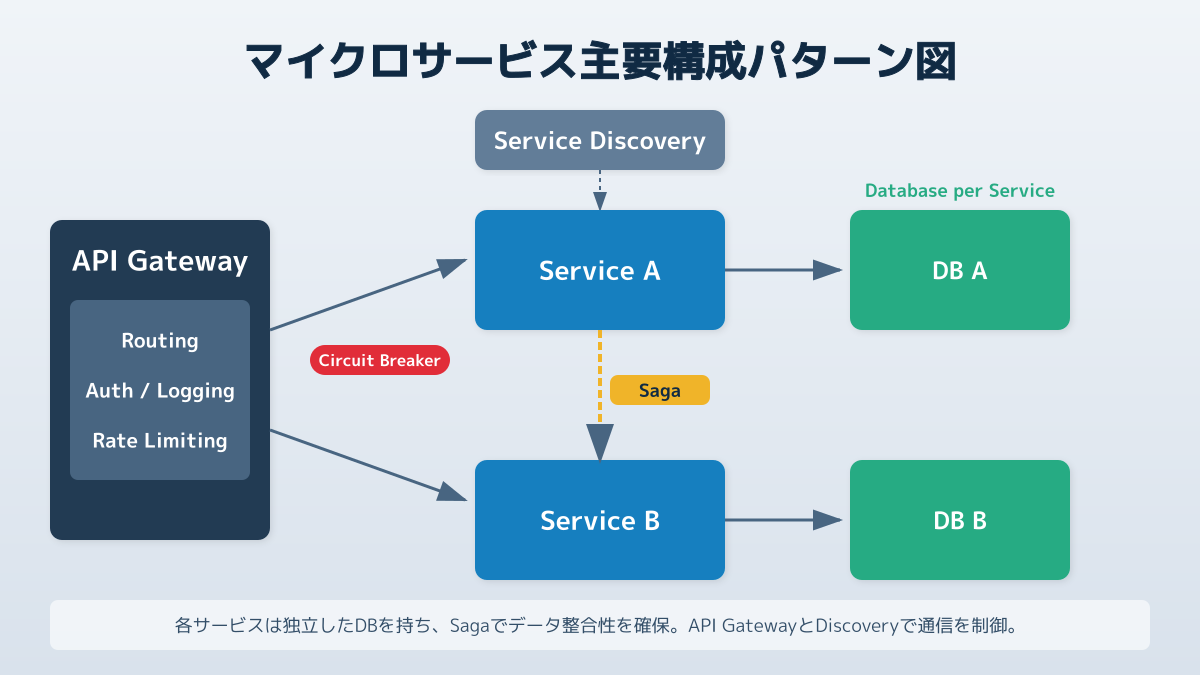
- API Gatewayパターン: クライアントとバックエンドサービスの間に単一のエンドポイントを設け、リクエストのルーティングや認証、負荷分散を集約します。AWS API GatewayやKongなどのツールがよく利用され、クライアント側の実装がシンプルになり、セキュリティ管理も一元化できます。
- Database per Serviceパターン: 各マイクロサービスが独自のデータベースを持つ設計です。他のサービスが直接データベースにアクセスすることを禁じ、必ずAPI経由でデータをやり取りすることで、サービス間の密結合を防ぎます。
- Sagaパターン: 複数のサービスにまたがる分散トランザクションを管理する手法です。各サービスでローカルなトランザクションを実行し、失敗した場合は補償トランザクション(取り消し処理)を連鎖的に実行してデータの整合性を保ちます。
- Circuit Breakerパターン: 特定のサービスに障害が発生した際、そのサービスへのリクエストを一時的に遮断(フォールバック)する仕組みです。システム全体がダウンする連鎖障害を防ぐために不可欠であり、NetflixがOSSとして公開したHystrixによって広く普及しました。
- Service Discoveryパターン: 動的に増減するマイクロサービスのネットワーク上の位置(IPアドレスやポート)を自動的に検出し、ルーティングを可能にする仕組みです。KubernetesのServiceリソースなどが代表例です。
アーキテクチャの判断基準
これらのパターンを導入する際、すべてのプロジェクトで一律に採用すればよいわけではありません。ビジネス要件と開発リソースのバランスを見極める判断基準が存在します。
第一の判断基準は、 トランザクションの厳密性 です。ECサイトの在庫引き当てと決済処理のように、絶対にデータの不整合が許されない業務プロセスでは、Sagaパターンの導入が必須となります。一方で、SNSの「いいね」機能のように、多少の遅延や結果整合性が許容される機能であれば、非同期のイベント駆動アーキテクチャを採用し、実装コストを抑える判断が適切です。
第二の判断基準は、 トラフィックの規模とクライアントの多様性 です。Webブラウザ、モバイルアプリ、外部パートナー向けAPIなど、複数のクライアントが存在する場合は、API Gatewayパターンを導入してクライアントごとの要件(ペイロードの最適化やプロトコル変換)を吸収するべきです。逆に、社内向けの単一Webアプリケーションのみを想定した初期のMVP(Minimum Viable Product)開発であれば、API Gatewayの構築コストがオーバーヘッドになるため、直接サービス間通信を行うシンプルな構成から始めることも選択肢に入ります。
現場で運用する際の注意点
マイクロサービスアーキテクチャを現場で運用する上で、最も注意すべきは 障害の局所化 と 運用負荷の増大 です。
サービスが細分化されると、1つのリクエストが複数のサービスを経由して処理されるため、どこでエラーや遅延が発生しているかの特定が困難になります。そのため、分散トレーシング(リクエストの追跡)や統合ログ管理の仕組みを初期段階から組み込む必要があります。
また、Database per Serviceを採用した場合、サービス間のデータ結合(JOIN)をデータベースレベルで行うことができません。CQRS(コマンドクエリ責務分離)パターンなどを併用し、参照専用のデータベースを構築してパフォーマンスを最適化する工夫が求められます。しかし、これはデータの同期遅延(結果整合性)を引き起こすため、「データが常に最新であるとは限らない」という前提に立ったUI/UX設計をビジネスサイドと合意しておくことが重要です。
選定の要点整理
ここまでの要点を整理すると、アーキテクチャ設計におけるポイントは以下の通りです。
- 課題解決に直結するパターンを選ぶ: API GatewayやSagaなどのマイクロサービスパターンは、分散システム特有の課題を解決する手段です。目的なく導入するのではなく、解決したいビジネス課題に合わせて選定します。
- 整合性と可用性のトレードオフを見極める: 分散トランザクションの複雑さを理解し、厳密なデータ整合性が必要な領域と、結果整合性で許容できる領域を明確に切り分けます。
- 障害を見越した防御的設計を徹底する: Circuit Breakerなどを活用し、一部のサービス障害がシステム全体を停止させない設計(フォールバック)を組み込みます。
これらの要点を押さえ、自社の開発体制やプロダクトの成長フェーズに適したアーキテクチャ設計を行うことが、マイクロサービスのメリットを最大化する鍵となります。
原則4:システムを繋ぐマイクロサービスAPIの設計と連携
マイクロサービスアーキテクチャを採用する際、各サービスが独立して稼働するだけではシステム全体としての価値を提供できません。サービス同士を繋ぐ通信インターフェースの設計が、システム全体のパフォーマンスや可用性を大きく左右します。ここでは、通信方式の選定や連携に関する基本事項と、現場で運用する際の具体的な注意点を整理します。
通信方式の選定と連携設計
マイクロサービスアーキテクチャにおいて、サービス間の通信は主にネットワーク越しに行われます。そのため、どのような通信方式を採用し、どのようにシステムを連携させるかが極めて重要な判断基準になります。
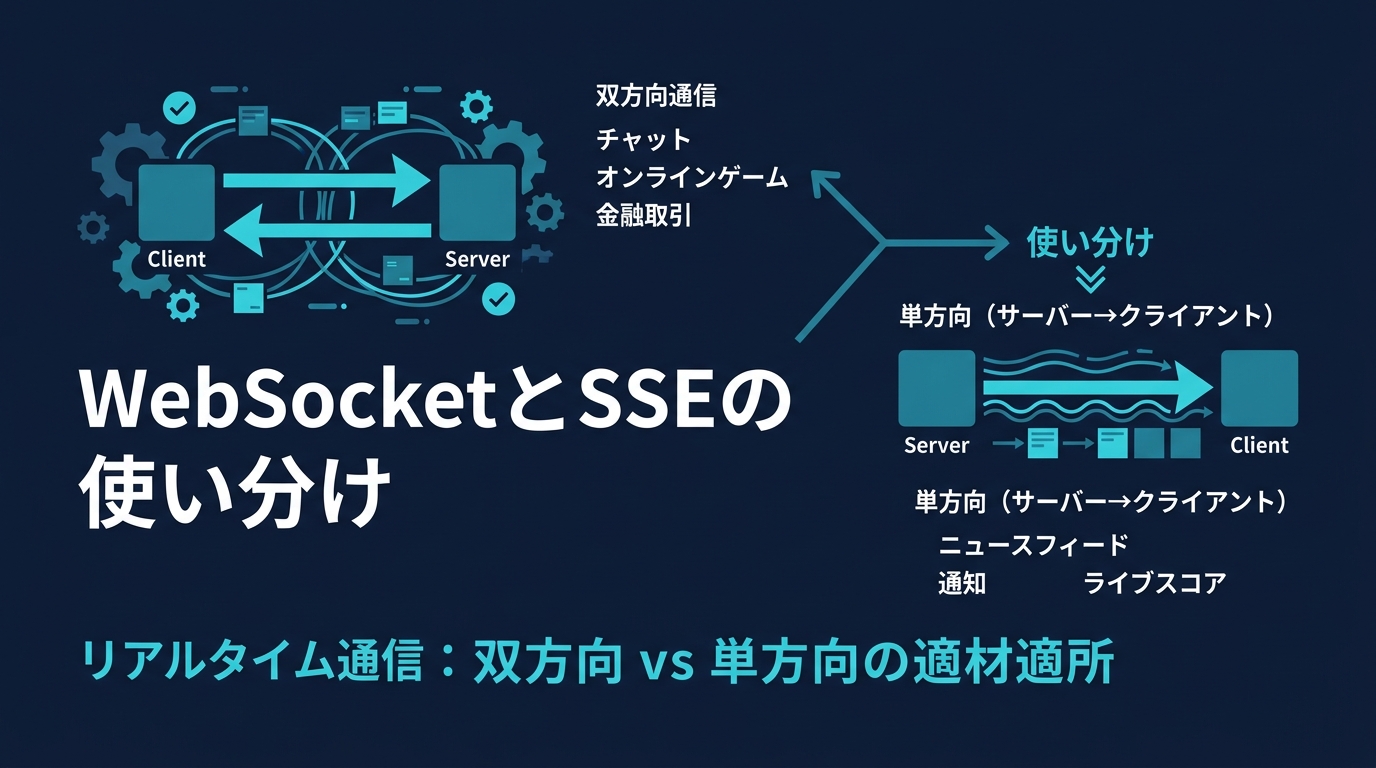
通信方式は大きく 同期通信 と 非同期通信 に分けられます。同期通信は、リクエストに対して即座にレスポンスを返す方式であり、REST APIやgRPCが代表的です。リアルタイムなデータ取得や、ユーザーの画面描画に直結する処理に適しています。一方で、呼び出し先のサービスが応答するまで待機するため、ネットワークの遅延や相手先サーバーの負荷が直接自サービスに影響するというデメリットがあります。
非同期通信は、メッセージキューやイベントバス(RabbitMQやApache Kafkaなど)を介してデータをやり取りする方式です。送信側はメッセージをキューに送るだけで自身の処理を完了できるため、システム間の結合度を低く保ち、高いスケーラビリティを実現できます。時間のかかるバックグラウンド処理や、即時性を求められないデータ同期などに適しています。
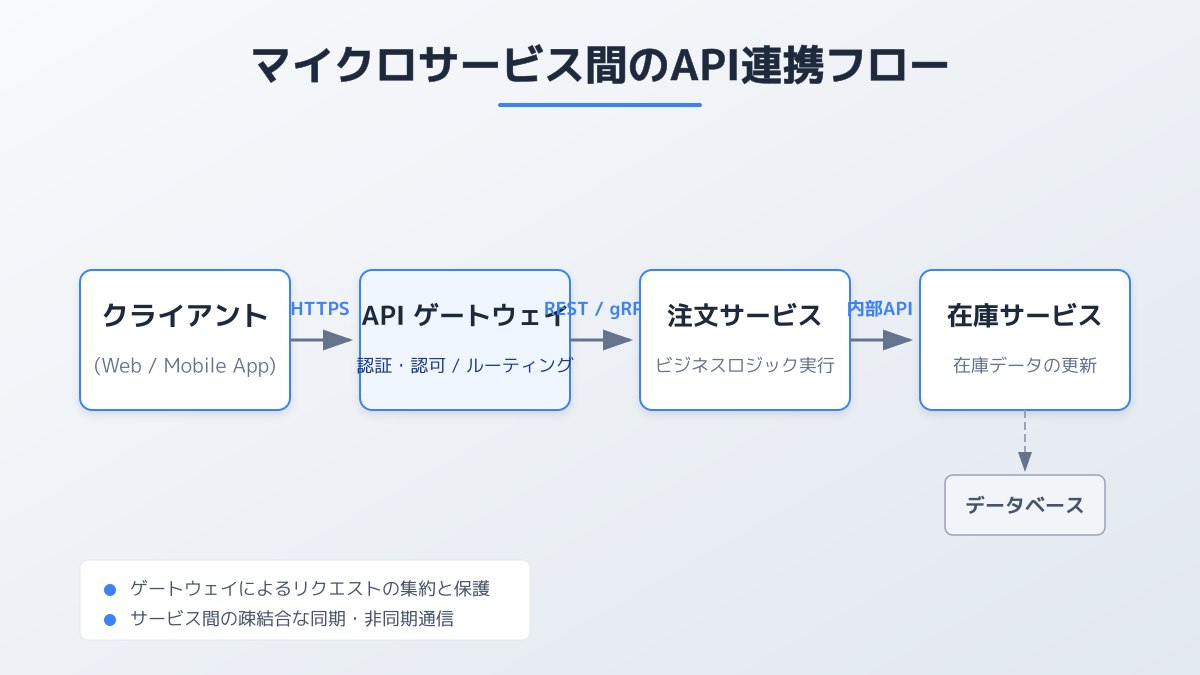
これらの方式を選ぶ際は、「その処理にリアルタイム性が必須か」「システム全体の負荷をどう分散させるか」「データの整合性をどのレベルで保証するか」という要件に基づいて判断します。すべてを同期通信で構築するのではなく、適材適所で非同期通信を組み合わせることが、堅牢なシステム構築の鍵です。なお、エンドポイントの命名規則やバージョニングの設計ルールについては、APIエンドポイントとは?設計・命名規則・セキュリティを完全解説 も参考にしてください。
インターフェース互換性の維持
実際にシステムを現場で運用する際、連携部分においていくつかの課題が発生します。特に注意すべきは、インターフェースのバージョン管理と、障害の連鎖(カスケード障害)の防止です。
まず、各サービスは独立したチームによって開発・デプロイされるため、あるサービスの仕様が変更された際、それに依存する他のサービスが予期せず停止してしまうリスクがあります。これを防ぐためには、マイクロサービスAPIの後方互換性を厳密に維持し、適切なバージョン管理(URIへのバージョン番号付与や、リクエストヘッダーでの指定など)を行う運用ルールをチーム間で合意しておく必要があります。
また、ネットワーク通信を前提とする以上、通信遅延や一時的なタイムアウトは日常的に発生するものとして設計しなければなりません。一つのサービスの障害がシステム全体に波及するのを防ぐ手段として サーキットブレーカーパターン の導入が定石です。これは、エラーが一定回数続いた場合に呼び出しを遮断し、代替となるデフォルト値を返したり、素早くエラーを返したりすることで、リソースの枯渇とシステム全体のダウンを防ぐ仕組みです。
API連携の要点整理
ここまでのAPI連携の要点を押さえるため、以下の3つの要素に整理します。
- 通信方式の適切な選択: ビジネス要件に応じて、RESTやgRPCなどの同期通信と、メッセージキューを用いた非同期通信を明確に使い分けることが不可欠です。
- 互換性の維持とバージョン管理: 独立したデプロイサイクルを妨げないよう、インターフェースの変更時には後方互換性を保ち、他サービスへの影響を最小限に抑えます。
- 障害への備えと切り離し: ネットワーク越しの通信であることを前提とし、サーキットブレーカーやリトライの仕組みを導入して障害の連鎖を物理的・論理的に防ぎます。
これらの要点を整理し、設計段階から通信の信頼性を担保することが、スケーラブルで可用性の高いプロダクトを実現するための強固な基盤となります。
原則5:サービスごとのデータベース分割と一貫性管理
マイクロサービスアーキテクチャを成功させる上で、避けて通れないのがデータ管理の戦略です。ここでは「データベースの分割(Database per Service)」という観点から、システムの独立性と拡張性を高めるための基本事項や、現場での具体的な注意点を整理します。
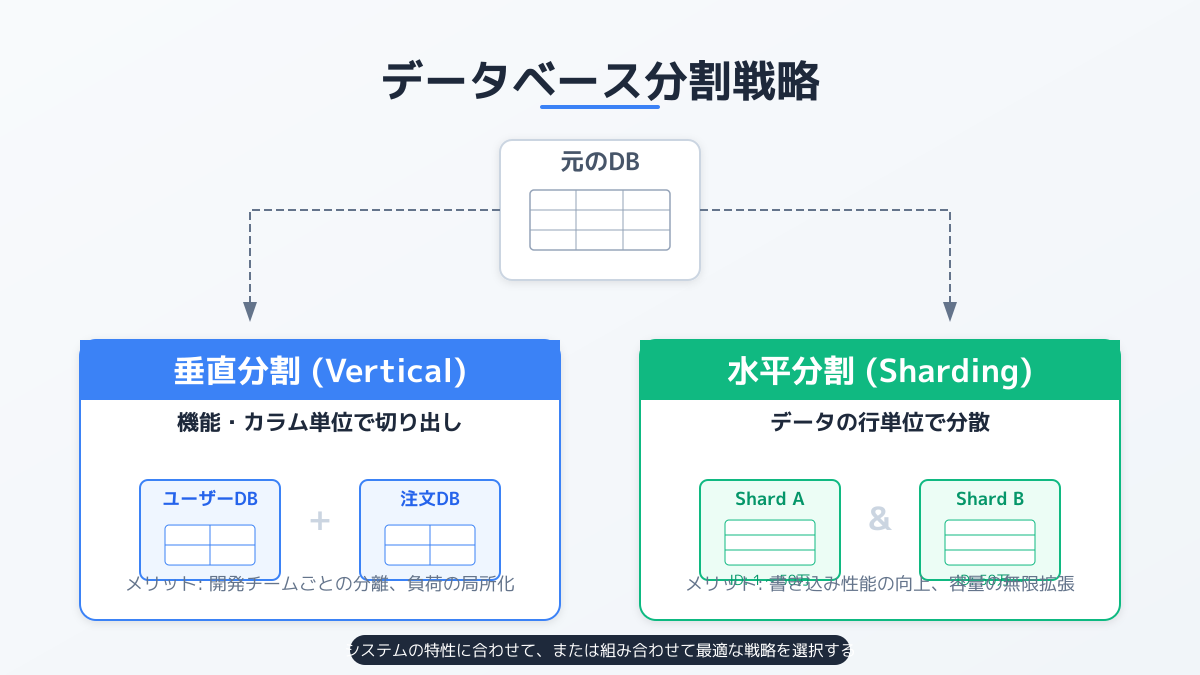
独立したデータストアのメリット
マイクロサービスアーキテクチャでは、各サービスが自身のデータをカプセル化し、他のサービスから直接データベースにアクセスさせない Database per Service パターンが基本となります。これにより、あるサービスのデータベーススキーマを変更しても、他のサービスに影響を与えない疎結合なシステムを実現できます。また、各サービスは要件に合わせて、リレーショナルデータベースやNoSQLなど、自身の特性に最も適したデータストアを自由に選択できるという利点もあります。
分割の判断基準
データベースを分割するかどうかの最大の判断基準は、ビジネス機能の境界とトランザクションの範囲です。従来の共有データベースを使用するシステムでは、複数のテーブルにまたがるACIDトランザクションが容易でした。しかし、サービスごとにデータベースを分割すると、この強力な一貫性を維持することが難しくなります。
そのため、「強い一貫性が常に必要なデータ群か、結果整合性で許容できるデータ群か」を厳密に評価する必要があります。もし強い一貫性が不可欠であり、常に同時に更新されるべきデータであれば、無理に分割せず同じサービス内に留める判断も重要です。
分散トランザクションの課題
データベースを分割したシステムを現場で運用する際、最も直面しやすい課題が分散トランザクションと、複数サービスにまたがるデータ取得です。
複数のサービス間でデータの整合性を保つためには、 Sagaパターン のような非同期メッセージングを用いた補償トランザクションを実装する必要があります。処理の途中でエラーが発生した場合、それまでの処理を取り消すための逆の操作を各サービスに実行させる仕組みです。
また、複数のデータベースからデータを結合して画面に表示する要件に対しては、APIゲートウェイでのデータ結合(API Composition)や、読み取り専用のビューを構築する CQRS (コマンドクエリ責務分離)パターンの導入が求められます。これらはシステムの複雑性を大幅に引き上げるため、運用チームの技術力と障害時のトレーサビリティ(分散トレーシング)の確保が不可欠です。
データベース分割戦略の要点整理
データベースの分割は、開発チームの自律性とプロダクトのスケーラビリティを担保するための強力な手段ですが、同時にデータの一貫性管理という新たな課題を生み出します。
要点を押さえるためには、まずはビジネス上のトランザクション境界を正確に見極め、不必要な分割を避けることが重要です。その上で、結果整合性を許容できるアーキテクチャ設計を行い、SagaやCQRSといった適切なデザインパターンを適用することで、運用負荷を抑えながら堅牢なシステムを構築できます。
原則6:分散システムにおける可観測性の確保
システムを複数の独立したサービスに分割するマイクロサービスアーキテクチャでは、障害発生時の原因特定が極めて困難になります。単一のアプリケーションで完結していたモノリス時代とは異なり、ユーザーからの1つのリクエストが多数のサービスを横断して処理されるためです。この分散システム特有のブラックボックス化を防ぐための基本事項が、「可観測性(オブザーバビリティ)」の確保です。システムの内部状態を外部から正確に把握できる状態を作らなければ、ダウンタイムの長期化によるビジネスの機会損失を招きます。
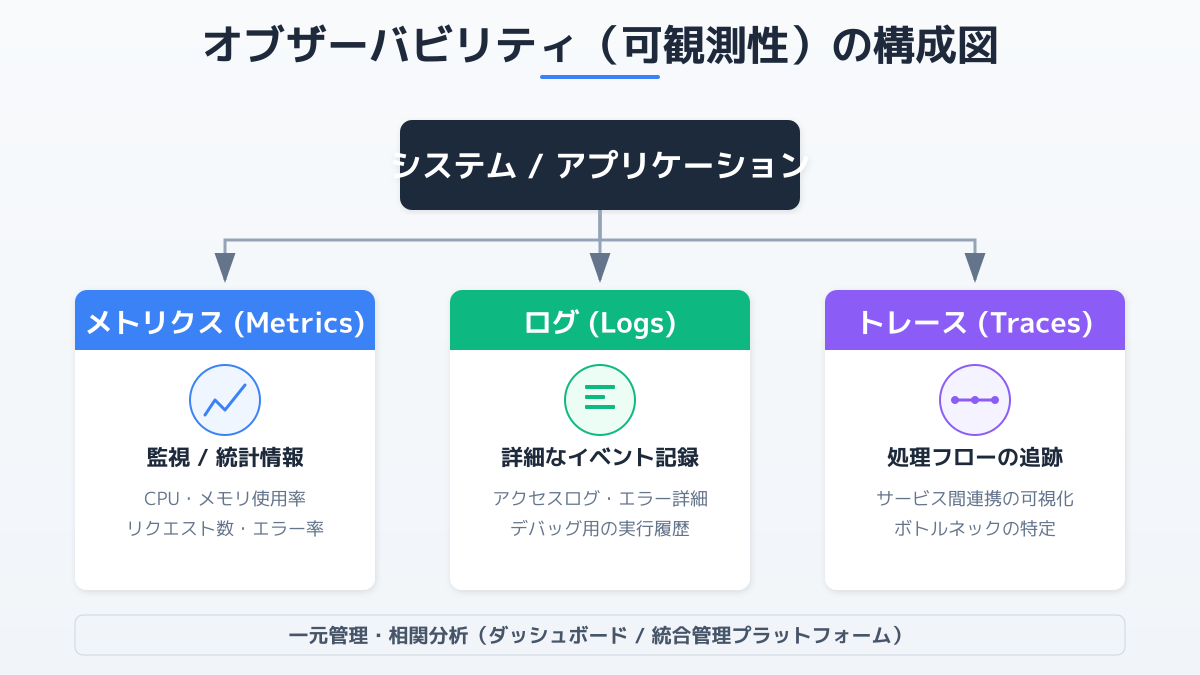
可観測性を実現するための判断基準は、監視基盤に対する適切な技術選定とアプローチにあります。具体的には、以下の3つの要素を組み合わせて導入を検討します。
- ログの集約: 各サービスが個別に出力するログを、一元的なログ管理基盤(DatadogやElasticsearchなど)に集約します。これにより、複数のサーバーにログインしてログを探す手間を省きます。
- 分散トレーシング: リクエストの入り口で一意の「トレースID」を付与し、各サービス間の通信で引き回します。JaegerやAWS X-Rayなどのツールを活用することで、処理の経路を可視化し、どのサービスがボトルネックになっているかを即座に特定できます。
- メトリクス監視: インフラ指標だけでなく、レスポンスタイムやエラー率などのアプリケーション指標を継続的に収集し、PrometheusやGrafanaなどのダッシュボードでシステムの健康状態を把握します。
これらの仕組みを現場で運用する際には、組織横断でのルール作りが不可欠です。最大の注意点は、全開発チームでログのフォーマットを統一することです。サービスごとにログの出力形式が異なると、横断的な検索や分析が機能しません。また、アラートの最適化も重要です。サービス間通信が増える環境では些細なタイムアウトが頻発しやすいため、すべてを通知すると現場が重要な障害を見落とす「アラート疲れ」を引き起こします。ユーザーの決済失敗など、ビジネスへの影響度が高い指標に絞ってアラートを設定する必要があります。
運用監視の仕組みを開発の最終盤ではなく、初期のアーキテクチャ設計の段階から組み込むことが最大の鍵となります。高度な可観測性を確保するための基盤構築に初期段階でリソースを投資することで、運用フェーズにおける障害の検知から復旧までの時間を劇的に短縮でき、結果として信頼性の高いプロダクトを維持し続けることが可能になります。
原則7:組織構造とチーム体制の最適化

マイクロサービスを成功に導くためのポイントは、技術的な分割だけでなく組織構造を最適化することです。システム設計はそれを構築する組織のコミュニケーション構造を反映するという「コンウェイの法則」が示す通り、アーキテクチャとチーム体制は密接に連動しています。
クロスファンクショナルなチーム編成
マイクロサービスアーキテクチャの最大のメリットは、各サービスを独立して開発・デプロイできる点にあります。しかし、これを実現するためには、開発チーム自体もサービスごとに独立していなければなりません。フロントエンド、バックエンド、インフラといった職能型のチーム編成ではなく、1つのビジネス機能(ドメイン)に対して責任を持つ クロスファンクショナルなチーム を編成することが基本事項となります。
チーム自律性の確保
組織構造の観点からマイクロサービスアーキテクチャの導入を判断する際は、 チームの自律性 が確保できるかが重要な指標となります。具体的には、以下のポイントを検証します。
- チームの境界とシステムの境界(API)が一致しているか
- 各チームが他チームの承認を待たずに、独自のタイミングでリリースできる権限を持っているか
- 1つのチームが管理するサービスの範囲が、メンバーの認知負荷を超えていないか
これらの条件を満たせない場合、システムだけを細かく分割しても、かえってコミュニケーションコストが増大し、開発スピードが低下するリスクがあります。
チーム間の依存関係管理
現場で運用フェーズに入ると、チーム間の依存関係が新たな課題となります。あるサービスのAPI仕様変更が、別のサービスを開発するチームの障害を引き起こすケースは少なくありません。これを防ぐためには、APIのバージョン管理と後方互換性の維持を徹底するルール作りが必要です。
また、各チームがインフラ構築やCI/CDパイプラインの整備に時間を奪われないよう、共通基盤を提供するプラットフォームチームを組成することも効果的です。
チーム編成の要点を整理すると、システムの分割単位とチームの管轄範囲を一致させ、各チームが自律的に動ける環境を整えることが不可欠です。技術的な連携手法だけでなく、開発を支える組織のあり方を見直すことが、アーキテクチャの恩恵を最大限に引き出す鍵となります。
原則8:運用監視基盤と障害対応ルールの確立
マイクロサービスアーキテクチャを成功に導く最後の原則は、システム全体の可視化と運用監視のルール作りです。サービスが細かく分割されることで、単一の障害がどこで発生し、どのように連鎖しているのかを追跡することが難しくなります。
監視ツールの導入と切り分け
導入時の判断基準として、各サービスを横断してリクエストを追跡できる分散トレーシングや、ログの集中管理基盤を初期段階で構築できるかが問われます。運用負荷が開発のメリットを上回らないよう、監視ツールの導入コストとチームの技術スタックを慎重に比較検討します。
障害対応プロセスの明確化
現場で運用する際の注意点は、障害発生時の切り分けプロセスを明確にしておくことです。サービス間の依存関係が複雑になるため、アラートが鳴った際に「どのチームが一次対応すべきか」を即座に判断できる体制づくりが欠かせません。
運用監視体制の要点を整理すると、技術的な監視基盤の構築と、それに対応する組織的な運用ルールの両輪を揃えることが重要です。マイクロサービスアーキテクチャの恩恵を最大限に引き出すためには、開発だけでなく、運用フェーズを見据えた設計を初期段階から組み込んでおく必要があります。
まとめ
本記事では、マイクロサービスアーキテクチャを成功に導くための8つの実践的な原則を解説しました。その要点は、ビジネス要件に基づいた適切なサービス分割と境界設計に始まり、システム要件に応じたマイクロサービスパターンの選定、そして堅牢なAPI連携やデータ管理戦略の確立です。
特に、分散システム特有の課題に対応するため、初期段階からの可観測性(オブザーバビリティ)確保と運用監視基盤の構築が不可欠です。また、コンウェイの法則が示す通り、技術的なアーキテクチャと組織構造を同期させ、チームが自律的に動ける環境を整えることも成功の鍵となります。これらの要素を総合的に考慮し、技術と組織の両面から最適化を図ることで、ビジネスの俊敏性とシステムの拡張性を両立するマイクロサービスアーキテクチャを実現できるでしょう。
この記事を書いた人

コセケン
テクラル合同会社
スタートアップでのCTO経験を経て、現在はテクラル合同会社にてシステム開発全般を牽引しています。アプリおよびWebの開発から、バックエンド、インフラ構築に至るまで幅広い技術領域に対応可能です。スピード感を持った品質の高いシステム開発を得意としており、新規プロダクトの立ち上げを一気通貫で支援します。本ブログでは実践的な開発ノウハウを発信していきます。